[Azure] Azure Services - AI Speech
카테고리: Azure
🎯 Azure Services - AI Speech
Azure Services에 있는 AI Speech Service에 대해 알아보자.
- Azure는 많은 기능이 빠르게 변화하고 있으므로 캡처한 이미지는 참고만 하자.
- Azure AI Speech는 음성 인식, 음성 합성, 음성 번역, 음성 번역 등의 기능을 제공한다.
- 기계 학습 기술 (DNNs)을 활용하여 서비스가 학습 데이터에서 학습하고 시간이 지남에 따라 정확도와 자연스러움을 향상시킬 수 있도록 한다.
1. 📦 Azure AI Speech Service에 사용된 학습 데이터
- Microsoft가 사용하는 독점 데이터
- 전화 대화 같은 다양한 출처의 녹음된 음성 데이터
- Skype 및 Cortana와 같은 다양한 제품과 서비스를 통해 수년간 축적된 음성 데이터
- 공개적으로 이용 가능한 데이터 세트
- Wall Street Journal 및 Switchboard 데이터 세트와 같은 잘 알려진 음성 코퍼스
- 의료 음성 데이터와 같은 특정 용례를 위한 더 전문화된 데이터 세트
2. ✨ 제공되는 기능
Speech와 관련된 다양한 서비스들을 시나리오에 맞춰서 제공
- Speech-to-Text(STT)
- 음성을 텍스트로 변환
- Text-to-Speech(TTS)
- 텍스트를 음성으로 변환
- Speech Translation
- 음성을 실시간으로 번역
- Speaker Recognition
- 음성 인식을 통해 특정 화자를 식별
- Keyword Recognition
- 음성 데이터에서 특정 키워드를 식별
- Pronunciation Assessment
- 발음 평가
- Language Identification
- 음성 데이터의 언어 식별
2.1 Speech-to-Text(STT)
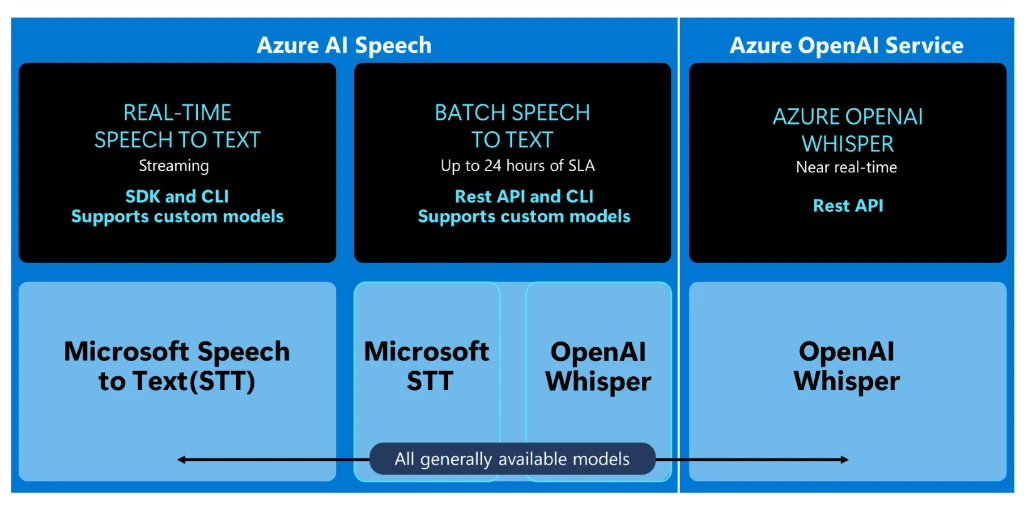
Azure AI Speech는 실시간 및 배치 음성 변환을 모두 지원하여 오디오 스트림을 텍스트로 변환하는 다양한 솔루션을 제공한다.
- Azure는 최근 OpenAI의 음성 인식 기술인 Whisper를 GA로 발표했다.
- 이제 Azure 사용자는 기존의 MS STT에 추가로 OpenAI의 Whisper 모델을 Azure에서 손쉽게 사용할 수 있다.
Azure OpenAI 서비스를 통한 Whisper 모델이 적합한 경우:- 오디오 파일을 한 번에 하나씩 신속하게 변환
- 다른 언어의 오디오를 영어로 번역
- 모델의 출력을 안내하는 프롬프트 제공
- 지원 되는 파일 형식: mp3, mp4, mpeg, mpga, m4a, wav, webm
Azure AI Speech를 통한 Whisper 모델이 적합한 경우:- 25MB보다 큰 파일(최대 1GB) 변환. Azure OpenAI Whisper 모델의 파일 크기 제한은 25MB
- 대용량 오디오 파일 배치 변환
- 대화에 참여하는 다양한 화자를 구분하기 위한 화자 분리. 음성 서비스는 특정 발화 부분을 말한 화자 정보를 제공. Azure OpenAI Whisper 모델은 화자 분리를 지원하지 않음
- 단어 수준 타임스탬프
- 지원되는 파일 형식: mp3, wav, ogg
- 시나리오에 맞게 정확도를 향상시키기 위한 Whisper 기본 모델의 커스터마이징(곧 제공 예정)
이미지 출처: Accelerate your productivity with the Whisper model in Azure AI now generally available
2.2 Text-to-Speech(TTS)
음성 합성이라고도 하는 텍스트 음성 변환 기능을 통해 애플리케이션, 도구 또는 장치에서 텍스트를 사람과 같은 합성 음성으로 변환할 수 있다.
- 기본 제공되는 사람과 같은 신경망 음성을 사용하거나, 제품 또는 브랜드에 고유한 맞춤형 신경망 음성을 생성할 수 있다.
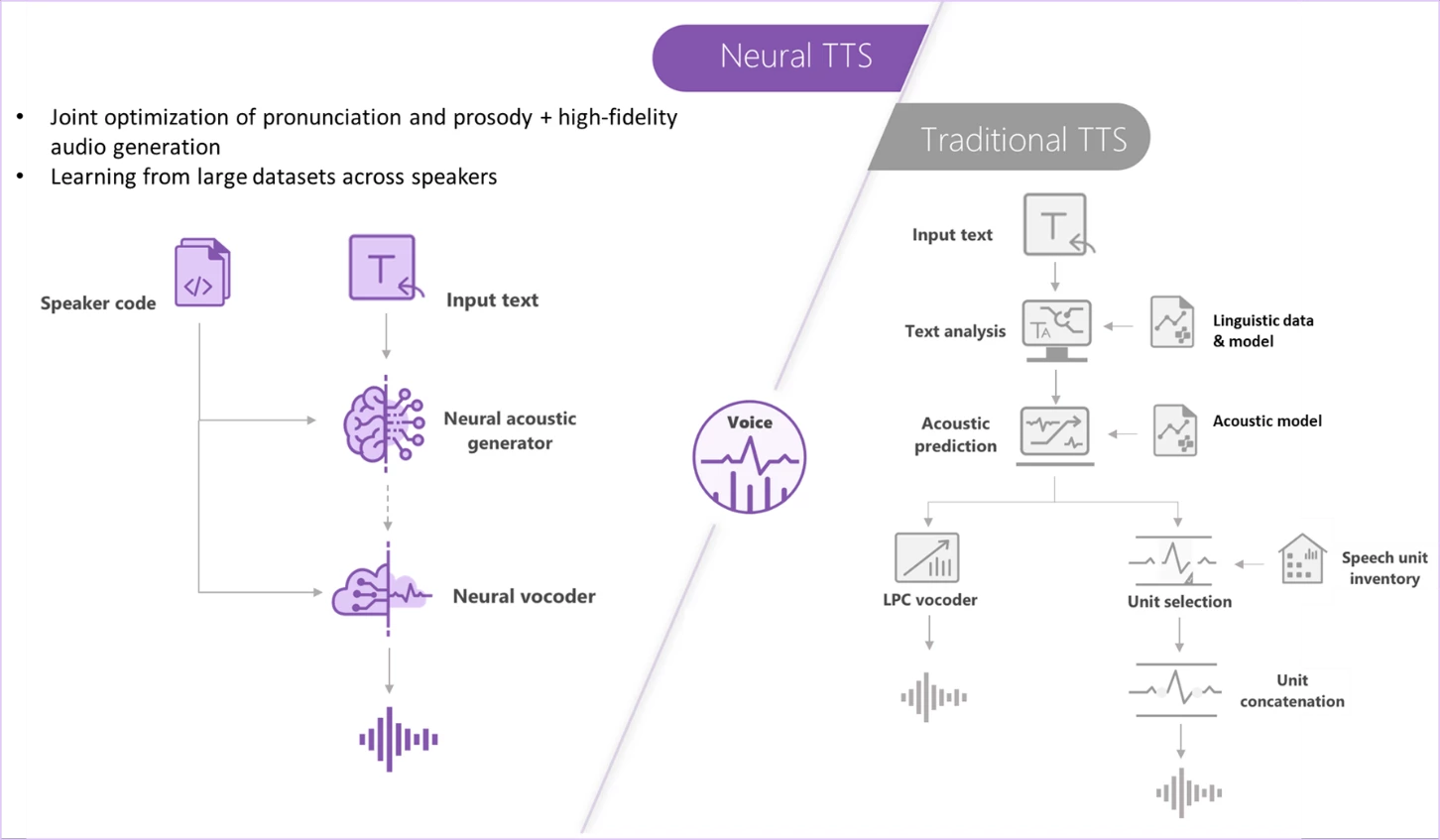
2.2.1 Neural voice (Neural TTS)
Neural voice (Neural TTS)는 기존의 TTS가 가진 부자연스러움을 극복하고자 제안된 방법이다.- Prosody: 말하는 언어의 강세나 억양 패턴
- 전통적인 접근 방법에서는
linguistic(언어학적) 특징과 acoustic(음향학적) 특징을 분리해서 처리한 후 합성하는데, 이때 이 과정에서의 불일치가 ‘부자연스러운’ 음성을 생성할 수 있음. - 예를 들어
record라는 단어가 명사일때와 동사일때 발음 및 스트레스가 달라지는데, 합성 과정에서는 이러한 것이 제대로 반영되지 않을 수 있음.
이미지 출처: Microsoft’s new neural text-to-speech service helps machines speak like people
2.2.2 Speech Synthesis Markup Language (SSML)
- 텍스트를 음성으로 변환할 때 발음, 억양, 속도, 볼륨 등 다양한 음성 특성에 대한 세부 지침을 제공하여 음성 합성을 제어하는 표준화된 마크업 언어
- SSML은 W3C(World Wide Web Consortium)에서 지정한 표준이다.
- Audio Contents Generation Lite 버전 사용해보기
| 요소 | 기능 설명 | SSML 표현 예시 |
|---|---|---|
| 발음 | 특정 단어나 구가 어떻게 발음되어야 하는지 지정한다. 이는 약어, 두문자어 및 고유 명사에 유용하다. | <say-as interpret-as="spell-out">NASA</say-as> |
| 음조 및 속도 | 음성의 음조(높거나 낮은 톤)와 속도(빠르기)를 조정할 수 있다. | <prosody pitch="high" rate="slow">이것은 예시입니다.</prosody> |
| 볼륨 | 텍스트의 소리 크기를 조정할 수 있다. | <prosody volume="loud">이것은 중요합니다!</prosody> |
| 휴지 | 음성 내에 지정된 길이의 일시 정지를 삽입할 수 있다. | <break time="500ms"/> |
| 강조 | 특정 단어나 구를 강조할 수 있다. | <emphasis level="strong">이것은 매우 중요합니다.</emphasis> |
| 음성 선택 | 텍스트의 다른 부분에 대해 다른 음성을 선택할 수 있다. | <voice name="en-US-Wavenet-D">안녕하세요, 이것은 남성 음성입니다.</voice><voice name="en-US-Wavenet-F">그리고 이것은 여성 음성입니다.</voice> |
| 언어 및 억양 | 텍스트의 일부에 대해 언어와 억양을 지정할 수 있다. | <lang xml:lang="fr-FR">Bonjour, je m'appelle Pierre.</lang> |
| 대체 발음 | 텍스트의 특정 부분에 대해 대체 발음 방법을 지정할 수 있다. | <sub alias="World Wide Web Consortium">W3C</sub> |
2.2.3 Speech Translation
- Speech 서비스는 Translation 서비스와 통합하여 다양한 시나리오에서의 번역기능을 제공한다.
2.2.4 Speaker Recognition
- 화자 인식이란 오디오 클립에서 말하는 사람을 식별하는 기술아다.
- 화자 인식에는 화자들의 음성을 학습한 후, 제공되는 오디오 샘플이 일치하는지 확인하는 화자 검증과 등록된 화자 그룹 내에서 알 수 없는 화자의 신원을 확인하는 화자 식별이 있다.
2.2.5 Keyword Recognition
- 키워드 인식은 오디오 스트림에서 단어나 짧은 문구를 검출해내는 작업으로 키워드 스팟팅이라고도 한다.
- 키워드 인식의 가장 일반적인 사용 사례는 가상 도우미의 음성 활성화이다.
- 예를 들어
Hey Cortana는 Cortana 도우미에 대한 키워드이다. - 키워드를 인식하면 시나리오별 작업이 수행된다.
- 가상 도우미 시나리오의 경우 일반적인 결과 작업은 키워드를 따르는 오디오의 음성 인식이다.
- 예를 들어
2.2.6 Pronunciation Assessment
- 발음 평가는 음성 인식 기능을 사용하여 언어 학습자에게 주관적이고 객관적인 피드백을 제공한다.
- 발음 연습과 적시에 피드백을 받는 것은 언어 능력을 향상시키는 데 필수적이다.
- 발음 평가는 언어 평가를 더 흥미롭고 모든 배경의 학습자들에게 더 접근 가능하게 만드는데 도움이 될 수 있다.
2.2.7 Language Identification
- 언어 식별은 오디오에서 지원되는 언어 목록과 비교하여 사용되는 언어를 식별하는 데 사용된다.